





最近,芯片专家唐杉博士更新了“AI芯片全景图”,同时加了版本号和发布时间,介绍了现有的几乎全部深度学习处理器,可能是对AI芯片厂商做的最全面的列表了。

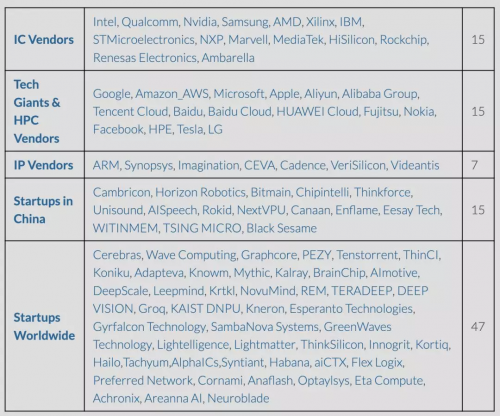
IC供应商(15家)科技巨头&HPC供应商(15家)IP供应商(7家)中国芯片初创公司(15家)全球芯片初创公司(47家)
集成电路供应商英特尔在Hot Chips大会,英特尔强调了“AI Everywhere”思想。
在2019年的Hot Chips大会上,英特尔公布了即将推出的高性能AI加速器的新细节:Intel®Nervana™神经网络处理器,其中NNP-T用于训练,NNP-I用于推理。英特尔的工程师展示了混合芯片封装技术、Intel® Optane™ DC持久内存和optical I/O技术的细节。
Mobileye EyeQMobileye目前正在开发其第五代SoC, 即EyeQ®5,作为一个视觉中央计算机,为将于2020年上路的全自动驾驶(5级)车辆执行传感器融合。为了满足功耗和性能目标,EyeQ®SoCs在最先进的超大规模集成电路工艺技术节点上进行了设计——第5代的FinFET达到了7nm。
MovidiusMYRIAD 2是一个多核、始终在线的芯片系统,支持移动、可穿戴和嵌入式应用程序的计算成像和视觉感知。视觉处理单元包含并行性、指令集体系结构和微体系结构特性,在一系列计算成像和计算机视觉应用程序(包括延迟要求低到毫秒级的应用程序)中提供高度可持续的性能效率。
Myriad™X是第一个以神经计算引擎为特征的VPU,这是一个用于在设备上运行深度神经网络应用程序的专用硬件加速器。通过智能存储结构和其他关键组件,神经计算引擎能够在避免数据流瓶颈的情况下,提供行业领先的性能。
Loihi测试芯片包括模拟大脑基本机制的数字电路,使机器学习更快、更高效,同时要求更低的计算能力。神经形态芯片模型的灵感来自神经元交流和学习的方式,使用的是可以根据时间来调节的spikes和plastic 突触。这可以帮助计算机自我组织,并根据模式和关联做出决策。
高通最近宣布,将通过Qualcomm® Cloud AI 100将公司的AI专业知识引入云计算,以满足云计算中AI推理处理的爆炸式需求,它利用了高通公司在先进信号处理和能耗效率方面的传统优势。
Snapdragon 855移动平台高通的设备上AI引擎骁龙855,其AI是前一代的3倍,每秒执行超过7万亿次操作(TOPS)。
在英伟达的SIGGRAPH 2018年主题演讲上,公司首席执行官黄仁勋正式公布了备受期待的Turing GPU架构。作为下一代NVIDIA GPU设计,Turing将纳入一些新功能,并将在今年推出。
英伟达的DGX-2系统具有强大的人工智能性能英伟达于今年3月推出了第二代DGX系统。为了制造半精度2 petaflops 的DGX-2,英伟达必须首先设计并制造一种新的NVLink 2.0 Switch芯片,名为NVSwitch。尽管英伟达目前只将NVSwitch作为其DGX-2系统的一个组成部分,但不排除向数据中心设备制造商销售NVSwitch芯片的可能。
三星三星为高端移动设备配备了Exynos 9系列9820处理器的设备上AI处理,定制核心和2.0Gbps LTE高级调制解调器支持丰富的移动体验,包括AR和VR应用
据报道,特斯拉正在与AMD合作开发自己的人工智能处理器,用于其自动驾驶系统。特斯拉与英伟达存在合作关系。英伟达的GPU为特斯拉的自动驾驶系统提供动力。
Xilinx赛灵思Xilinx推出了世界上最快的数据中心和人工智能加速卡:Alveo,旨在大幅提高跨云和内部数据中心的行业标准服务器的性能。
Xilinx提供了“从边缘到云的机器学习推理解决方案”,并且声称他们的FPGA最适合INT8。虽然FPGAs的每瓦性能令人印象深刻,但在价格和性能之间找到平衡是FPGAs的主要挑战。
IBM神经形态芯片TrueNorth:TrueNorth是IBM的神经形态CMOS ASIC与DARPA的SyNAPSE项目共同开发的。它是一个芯片设计上的多核处理器网络,有4096个核,每个核模拟256个可编程硅“神经元”,总共有100多万个神经元。反过来,每个神经元有256个可编程的“突触”来传递它们之间的信号。因此,可编程突触的总数超过2.68亿个。就基本的构建模块而言,它的晶体管数量是54亿。由于4096个神经突触核都能处理内存、计算和通信,TrueNorth绕过了von- neumann架构的瓶颈,而且非常节能,功耗70毫瓦,大约是传统微处理器功率密度的1/ 10000。
IBM POWER9,人工智能的顺风车:POWER9 处理器芯片专为人工智能设计,计算速度比前代 POWER8 产品高出 1.5 倍。
ST意法半导体正在设计神经网络技术的第二代产品,该公司在2017年2月的国际固态电路会议(ISSCC)上报告了这一技术。
NXPS32 AUTOMOTIVE PLATFORMNXP S32汽车平台是世界上第一个可扩展的汽车计算架构。它提供了一个统一的硬件平台和一个跨应用领域的相同软件环境,以更快地将丰富的车内体验和自动驾驶功能推向市场。
ADAS ChipS32V234是一个用于前置和环绕视图相机、机器学习和传感器融合应用的视觉处理器。
MarvellMarvell展示了人工智能SSD体系结构解决方案,通过将英伟达的深度学习加速器(NVDLA)技术整合到其数据中心和客户端SSD家族中beat365,为广泛的行业提供AI能力。
麒麟980,是世界上第一个7nm移动智能芯片。麒麟980创造了多项“全球第一”,是全球首款7nm制程手机SoC芯片组,全球首款cortex-A76架构芯片组,全球首款双NPU设计,全球首款支持LTE cat21的芯片组。麒麟980融合多种技术,引领AI流,为用户提供令人印象深刻的移动性能,创造更便捷、更智能的生活。
RenesasRenesas为下一代人工智能芯片开发了新的内存处理技术,使人工智能处理性能达到8.8 TOPS/W。
谷歌已经开始销售售价150美元的Coral Dev Board,这是一款用于加速人工智能边缘计算的硬件套件
去年I/O大会,谷歌发布了TPU 3.0,详细分析可以看这篇文章:谷歌 TPU 3.0 到底厉害在哪里?
Edge TPU如今,从消费者到企业应用程序,AI无处不在。随着连接设备的爆炸式增长,再加上对隐私/机密性、低延迟和带宽限制的需求,在云环境中训练的AI模型越来越需要在边缘运行。Edge TPU是谷歌的专用ASIC,设计用于在边缘运行AI。
亚马逊亚马逊可能正在为Alexa开发AI芯片,这将使Alexa能够更快地解析信息并得到答案。
AWS Inferentia,是一款高性能机器学习推理芯片,为AWS定制。AWS Inferentia以极低的成本提供高吞吐量、低延迟的推理性能。每个芯片提供数百TOPS的推理吞吐量,允许复杂的模型做出快速预测。为了获得更高的性能,可以同时使用多个AWS Inferentia芯片来驱动数千 TOPS的吞吐量上限。
AWS FPGA实例Amazon EC2 F1是一个带有现场可编程门阵列(FPGA)的计算实例,你可以通过编程为应用程序创建自定义硬件加速。
微软如果想了解微软对FPGA在云中的应用前景,基于FPGA的可配置云也是一个很好的参考。“智慧云中的FPGA”这篇文章提供了FPGA的概述和FPGA用于云端推理。
在微软Build开发者大会上,微软宣布了一个集成了Azure机器学习的项目Project Brainwave,该公司表示,这将使Azure成为最高效的人工智能云计算平台。
A12仿生,与下一代神经引擎一起,提供了令人难以置信的性能。它使用实时机器学习来改变你体验照片、游戏、增强现实等等的方式。
阿里成立了一家半导体公司,并公布了推出自己的人工智能处理器的计划。该公司希望加强对其云计算和物联网业务的支持。
阿里巴巴正在开发自己的神经网络芯片Ali-NPU,该芯片将用于图像视频分析、机器学习等人工智能应用场景。
阿里云FPGA云服务器(Beta)是阿里云提供的现场可编程门阵列(FPGA)的计算实例,用户可以在几分钟内轻松创建FPGA设计,并基于阿里云弹性计算框架创建定制的专用硬件加速器。
深度学习(Deep Learning)是一种多层计算模型,可以对复杂输入进行建模,在图像分类、语音识别、自然语言处理中取得了成果,FPGA 实例由于其细粒度并行的硬件特性,非常适合小批量数据的深度学习预测过程,以低功耗、低延迟、高性能著称,以 AlexNet 模型为例,使用 FPGA 计算实例进行图片类别预测,速度比仅用 CPU 的普通实例快 8~15 倍。
百度百度自研了AI芯片“昆仑”,瞄准云计算和边缘用例。该芯片采用三星的14nm制程,内存带宽为512GBps,每秒可运行260Tops,功率为100瓦。
在百度内部,FPGA 从 2013 年开始就应用在许多典型的深度学习模型中,如 DNN,RNN,CNN,LSTM 等,涵盖了语音识别,自然语言处理,推荐算法,图像识别等广泛的应用领域。百度 FPGA 云服务器中开放了基于 FPGA 的深度卷积神经网络加速服务,单卡提供 3Tops 的定点计算能力,支持典型深度卷积网络算子,如卷积、逆卷积、池化、拼接、切割等,有效加速典型网络结构如 VggNet、GoogLeNet、ResNet 等。基于 FPGA 的深度学习硬件,深度定制优化了主流深度学习平台如 caffe 等,用户可以直接将深度学习业务切换到 FPGA 平台,而无需考虑底层硬件细节。
华为发布了两款新的人工智能芯片昇腾910(Ascend 910)和昇腾310(Ascend 310),其中昇腾910在昨天宣布商用量产。这两款芯片的目标是用于数据中心和联网消费设备,此举使华为与高通和英伟达等主要芯片制造商展开竞争。
富士通富士通正在创建的DLU是从零开始的,它既不是基于Sparc也不是基于ARM指令集,事实上,它有自己的指令集和专门用于深度学习的新数据格式,这些都是从零开始创建的。
据招聘信息和知情人士透露,Facebook 正在组建一个团队来设计自己的芯片,这加剧了科技公司的一种趋势,即为自己供货,降低对英特尔和高通等芯片制造商的依赖。
特斯拉特斯拉开发了自己的自动驾驶芯片:尺寸为 260 平方毫米,拥有 60 亿晶体管,具有双核神经网络阵列,每秒可运行 36 万亿次操作,采用 14 纳米工艺制造。与上一代 Autopilot 硬件(由英伟达硬件驱动)相比,每秒帧数处理能力提高了 21 倍,使每辆车的硬件成本降低约 20%。
ARMDynamIQ是嵌入式IP巨头ARM对AI时代的回应。它可能不是一个性的设计,但肯定是重要的。
ARM还提供了一个开源计算库,其中包含为Arm Cortex-A系列CPU处理器和Arm Mali系列GPU实现的全面软件功能。
ML处理器专为边缘推理而设计,具有业界领先的4.6 TOP性能,移动设备和智能IP摄像机具有惊人的3 TOP/W效率。
Arm详细介绍了被称为“机器学习处理器(MLP)”的架构。MLP IP在架构实施方面起步空白,团队由从CPU和GPU团队中脱颖而出的工程师组成。
新思科技(Synopsys)名列美国标普500指数成分股,长期以来是全球排名第一的IC电子设计自动化(EDA)创新公司,也是排名第一的IC界面IP供应厂商,专门提供“硅晶到软件(Silicon to Software™)”最佳的解决方案。不论是针对开发先进半导体系统单芯片(SoC)的设计工程师,或正在撰写应用程序且要求高品质及安全性的软件开发工程师,新思科技都能提供所需的解决方案,以协助工程师完成创新、高品质并兼具安全性的产品。
基华物流(CEVA)由两大物流巨头TNT物流和EGL宏鹰全球物流于2007年8月合并组成。从2G开始,CEVA的DSP IP就被用在通信基带处理上,TeakLite系列非常成功。在4G时代,联芯基于CEVA DSP打造的SDR平台被小米采用。在CES之前,CEVA宣布了一款名为NeuPro的新型专用神经网络加速器IP。
益华电脑(Cadence)成立于1988年,是EDA(电子设计自动化)软件与工程服务的重要厂商,主要提供设计集成电路(IC)、系统单芯片(SoC)、以及印刷电路板(PCB)所需的软件工具与硅智财(IP)beat365官方最新版,涵盖类比/数位/混合电路设计、验证、封装/PCB设计等各领域。
芯原股份(VeriSilicon)芯原的前身是美国思略科技公司(Celestry Design Technologies,Inc.)在上海的分公司。目前是集成电路(IC)设计代工公司,为广泛的电子设备和系统如智能手机,平板电脑,高清电视(HDTV),机顶盒,蓝光DVD播放机,家庭网关以及网络和数据中心等提供定制化解决方案和系统级芯片(SoC)的一站式服务。
videantis德国videantis有限公司是面向移动、家用和定制多媒体应用的芯片、硅IP及软件解决方案的领先供应商,推出了支持多种标准的视频IP解决方案,包括 H.264/AVC、MPEG-4、H.263、DivX、WMV9/VC-1、MPEG-2和视频增强标准等。Videantis的v-MP6000UDX处理器是一个可扩展的处理器系列,旨在以低功耗的方式运行高性能深度学习,计算机视觉,成像和视频编码应用。
地平线(Horizon Robotics )受到中国企业和政府推动半导体产业的策略影响,地平线称在其最新一轮融资中筹集了6亿美元,其估值达到30亿美元。
比特(Bitmain)还不确定比特的最新产品Sophon是否会涉足深度学习。但是,通过赋予它这样一个名字,比特向AI之心已经非常明显了。Sophon将包括比特的第一块定制芯片,用于性的AI技术。如果一切顺利,Sophon很快就可以在世界各地的大型数据中心训练神经网络了。
启英泰伦(Chipintelli)启英泰伦的第一款IC CI1006专为自动语音识别应用而设计。
ThinkForce中国AI芯片制造商ThinkForce获得6800万美元A轮融资,红杉资本,高瓴资本集团,依图参与。
肇观电子(NextVPU)全球领先的计算机视觉处理IC和系统公司NextVPU推出了AI视觉处理IC N171。N171是NextVPU的N1系列计算机视觉芯片的旗舰IC。
燧原科技(Enflame Tech)燧原科技是一家总部位于中国上海的创业公司。燧原科技正在开发深度学习加速器SoC和软件堆栈,针对云服务提供商和数据中心的AI训练平台解决方案。
亿智电子(EEasy Technology)亿智电子是一家AI系统级芯片(SoC)设计公司和整体解决方案提供商。它的产品包括AI加速,图像和图形处理,视频编码和解码,混合信号ULSI设计能力。
知存科技(WITINMEM)知存科技成立于2017年10月,专注于基于NOR闪存中处理内存技术的低成本、低功耗AI芯片和系统解决方案。
清微智能科技(Tsing Micro)清微智能是一家可重构计算芯片企业,提供以端侧为基础,并向云侧延伸的芯片产品及解决方案,其核心技术团队来自清华大学微电子所。
黑芝麻智能科技(Black Sesame Technologies)黑芝麻智能科技将要完成其1亿美元的B轮融资,未来用于扩大与OEM的合作,加速大规模生产,自动驾驶仪的参考设计开发,以及软件车辆集成。
全球芯片初创公司Cerebras Systems为了给人工智能提供动力,这家初创公司制造了一个非常非常大的芯片
Cerebras Systems推出了有史以来最大的半导体芯片,其名为Cerebras Wafer Scale Engine,面积 42225 平方毫米(边长约22厘米),拥有1.2万亿晶体管,40 万核心。晶体管是硅芯片的基本组件,1971年,英特尔的第一个4004处理器拥有2300个晶体管,而最近的一个AMD的处理器拥有320亿晶体管。
Wave Computing一家位于美国硅谷、致力于推动人工智能深度学习从边缘计算到数据中心的计算加速方案的公司。
GraphcoreGraphcore是一家英国AI芯片公司,去年年底筹集了3000万美元,用于支持其智能处理单元IPU的开发。关于Graphcore的IPU架构,这篇文章做了一些分析:【XPU 时代】解密哈萨比斯投资的 IPU,他们要分英伟达一杯羹。
TenstorrentTenstorrent是一家位于多伦多的小型加拿大初创企业,与大多数企业一样,该公司声称,深度学习的效率有了一个数量级的提高。他们没有公开更多细节,但他们在 Cognitive 300名单上。
ThinCIThinCI筹集了6500万美元,用于开发用于汽车和联网车辆的AI处理器。ThinCI不仅在开发芯片,还在开发软件和开发工具包,使其硬件平台能够扩展到广泛的用途。
Koniku成立于2014年的加州初创公司Koniku目前已经获得165万美元的资金,成为“世界上第一家神经计算公司”。?Koniku实际上是将生物神经元集成到芯片上,并且已经取得了一些进展。
KnowmKnowm实际上是一家ORG,但他们似乎在追求营利。到目前为止,这家新成立的公司已经获得了数目不详的种子资金,用于开发一个新的计算框架AHaH Computing(Anti-Hebbian and Hebbian),这项技术旨在将智能机器学习应用程序的大小和功耗降低9个数量级。
MythicMythic正在开发一种AI芯片,它“将桌面GPU计算能力和深度神经网络植入一个纽扣大小的芯片——功率低50倍,数据处理能力也远超竞争对手”
DeepScale为感知人工智能(perception AI )筹集了300万美元,以确保自动驾驶汽车的安全性。


外媒称,麦肯锡全球研究院的最新报告显示,预计到2055年,全球经济体的有薪工作中,49%将借由改善现有科技而实现自动化,而受自动化影响最大的国家为中国与印度。 据新加坡《联合早报》1月17日报道,麦肯锡日前在港发布题为“未来产业:自动化、就业与生产力”的报告。报告指出,目前全球生产力增长放缓,而包括机械人技术、人工智能及机器学习等在内的自动化科技为不少国家的经济发展注入强心针,并有效减低因适龄劳动人口数量下降而带来的影响。 麦肯锡香港分公司总经理倪以理指出,自动化仍需数十年的时间才能充分发展,业内需要思考的是职业重新分配的问题。 报告显示,全球范围来看,可自动化的工作内容涉及相当于11亿名员工及11.9兆美元的薪酬,在中国、印度、
中国一站式 IP 和定制芯片企业芯动科技(INNOSILICON)发布:已完成全球首个基于中芯国际 FinFET N+1 先进工艺的芯片流片和测试,所有 IP 全自主国产,功能一次测试通过。 官方介绍称,自 2019 年始,芯动在中芯 N+1 工艺尚待成熟的情况下,团队投入数千万元设计优化,率先完成 NTO 流片。基于 N+1 制程的首款芯片经过数月多轮测试迭代,助力中芯国际突破 N+1 工艺良率瓶颈。 芯动科技与全球知名代工厂已有多年国产 IP 生态共建的合作,为大量国内和全球客户实现从成熟工艺(55nm、40nm、28nm、22nm 等)到先进工艺(如 FinFET 14nm、12nm、7nm 等)的不断跨越,在
问市 /
我国芯片企业众多,但都小而散,排名前10位的企业营业收入总和还不到美国高通的1/3, 行业急需产业大鳄出现,紫光收购展讯通信和锐迪科只是小试牛刀,接下来国家还将进一步扶持政策,重点支持十多家企业做大做强,使其迅速成长为具有国际竞争力的企业。 “可以说芯片产业整合时代已全面来临,以前那种散、多、小企业即将被大的企业集团所整合,国家下一步也将加大力度扶持集成电路产业,产业环境将会得到极大改善,产业将会迎来新一轮的高峰期。” 中国半导体行业协会执行副理事长徐小田告诉中国商报记者。 上海紫光集团在半年内收购了展讯通信和锐迪科,可以算得上中国芯片业的标志性事件。“紫光集团收购芯片龙头企业,与恒大进军足球圈极为相似,在他们收购
魅蓝将于9月20日于北京举行新品发布会,这次发布会的主角是魅蓝6。魅蓝6作为魅蓝的基本款虽然定位在入门级市场,但这次魅蓝给予了“Dare to basic”的口号,这次魅蓝要将基本款做到最好。目前已经有不少关于魅蓝6的消息曝光,下面我们来整理一下这些消息,看一下这次发布会有什么看点。 仿金属机身设计 ▲魅蓝6外观曝光 魅蓝6将会延续魅蓝系列的聚碳酸酯机身设计,但魅蓝6的后盖并不是简单的抛光处理器,而是用上了金属质感的喷涂,让手机无论视觉还是触感都有金属质感。另外,通过曝光的图片可以看到,魅蓝6的机身上有两条类似高光T槽的装饰带,给人一种金属机身的错觉。 MT6750处理器 ▲魅蓝6跑分 此次魅蓝6搭载了联发科
据《金融时报》英文网报道,在英国最新的财政预算中,英国政府对自动驾驶汽车和人工智能技术(AI)的投资力度大幅增加,达2.7亿英镑,并指出上述“破坏性技术”有望转变英国经济形势。下面就随汽车电子小编一起来了解一下相关内容吧。 英国 关于自动驾驶和人工智能 英国财政大臣菲利普 哈蒙德(Philip Hammond)宣布,英国新设立的“产业战略挑战基金”(Industrial Strategy Challenge Fund)将会大力辅助企业和英国科技基地之间的合作。哈蒙德表示2017-2018年,英国政府在自动驾驶汽车和AI技术领域将投资2.7亿英镑。 据报道,首批项目包括对电动汽车电池、药品生产新技术以及机器人系统等
Dialog半导体股份有限公司(德国法兰克福证券交易所股票代码:DLG)日前宣布推出全球首款2D/3D影像转换实时处理芯片:DA8223.该芯片为包括智能手机和平板电脑等在内的各种便携式设备提供了2D/3D视频影像实时转换处理的功能。该器件同时也集成了一个视差栅栏(parallax barrier)屏幕驱动器,允许用户在不需要眼镜的情况下观看3D内容。 该芯片对每一帧2D视频图像进行分析,通过分离前景图像和背景图像,创造出一个分层的深度映射图(Z-depth)。从而使每一个原有的图像像素都被映射到左眼和右眼,当通过带有视差栅栏的显示器观看时,就能直接渲染出3D图像效果。DA8223集成了完整的2D/3D图像转换
,为智能手机和平板电脑带来3D体验 /
10月12日,萤石在杭州举行“ 智无感 净无忧——2023清洁新品发布会 ”,带来了两款采用 具身理念研发 的清洁服务机器人新品。 扫拖宝20 Pro 支持AI智能融合避障,搭载主动切毛滚刷等创新技术,告别传统清洁困扰; 云视觉商用清洁机器人BS1 创新多目视觉计算系统ezMultiVCS++,在复杂环境下也能稳定运行。两款新品均融合了多项创新专利技术及AI视觉能力, 深刻感知、开启智能清洁时代 。 萤石AI扫拖宝RS20 Pro AI智能融合避障+主动切毛滚刷+拖布自动装卸 远离传统清洁困扰 萤石以用户为,针对家庭清洁中的 宠物场景、长发场景、地毯场景、高频场景 带来了全新的清洁解决方案——萤石AI扫拖宝RS20 Pr
业界人士称如果电脑技术继续按照现有的步伐发展,基于硅材料的芯片技术肯定将在10年之内退休,它会被更好的技术替代。 美国半导体行业协会总裁George Scalise日前表示:“我们现在处于挑选候选者的阶段。” 一般来讲,计算机行业当中,一项技术从实验室到商用要花大约10年时间,因此,替代现有硅片技术的产品实际已经在一些地方小范围地存在了。 IBM研发部门的高级副总裁John Kelly说:“我们已经拥有更多替代产品,假如我们仅有一个替代技术,我会相当忧虑。” 其中一种技术叫做“自旋电子”技术,通过电子充电和旋转的方法来携带信息。微处理器的基本建造单位“逻辑门”,如果使用自旋电子的方法能够大大减少耗电。 纽约州立大学奥尔巴
典型计算元素特性现有的计算元素(或处理器)具有不同的特性,这影响它们处理效率。下图显示了不同计算元素的处理效率与应用程序的处理特性 ...
在SoC中实现的计算单元当前的自动驾驶 先进驾驶辅助系统片上系统(SoC)通过集成不同计算特性的计算元件构建了计算组件,以实现对不同应用 ...
摄像头前处理流程•自动驾驶HDR:为适应自动驾驶所处的高动态范围环境,先进的图像传感器采用同时多曝光和 或拆分像素设计。组合不同曝光可 ...
ISP接口 连接具体的传感器选择(如摄像头)不在讨论范围内。但是,任何系统功能模块(如感知)消费的处理后的图像数据在讨论范围内。感知功 ...
功能模块图基准测试基准测试活动主要围绕两个方面:•对应于功能模块图构建模块的基准测试。例如深度学习推理基准测试,这是感知和其他模块 ...

站点相关:嵌入式处理器嵌入式操作系统开发相关FPGA/DSP总线与接口数据处理消费电子工业电子汽车电子其他技术存储技术综合资讯论坛电子百科